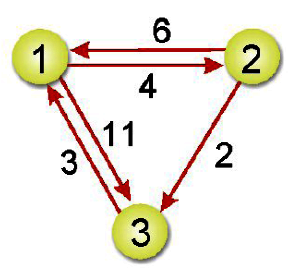
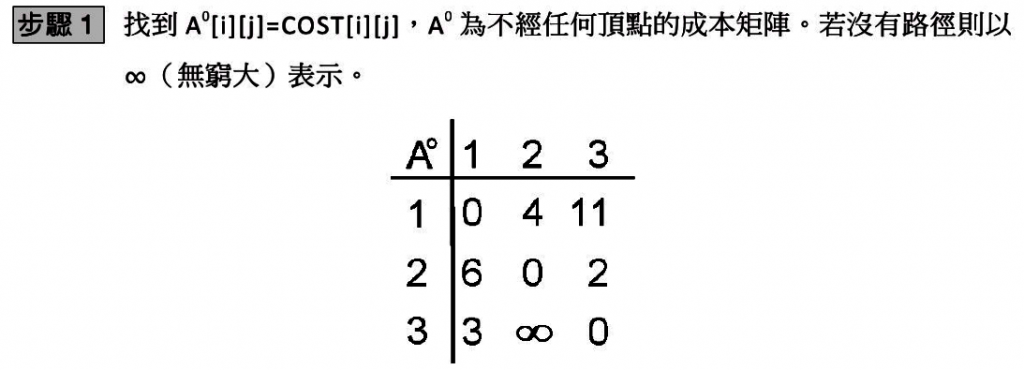
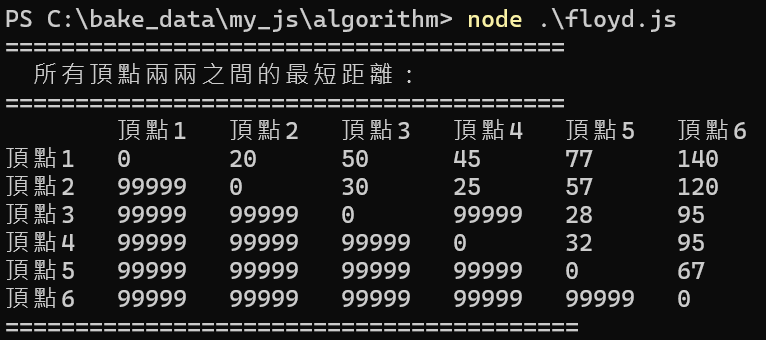
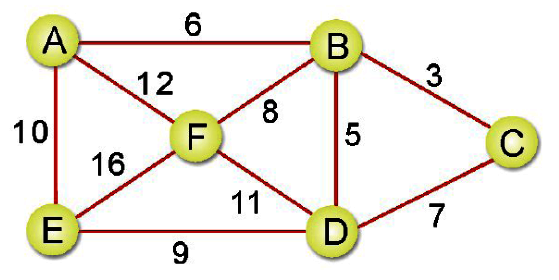
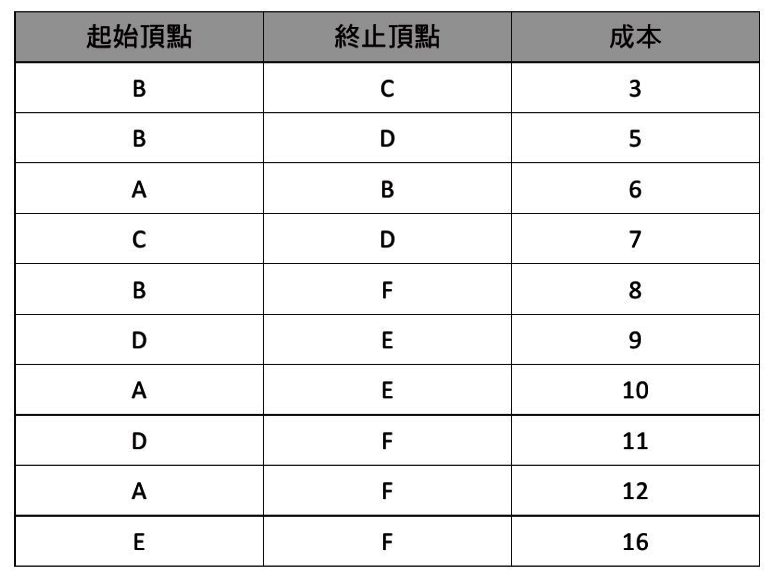
完美實戰安全性演算法
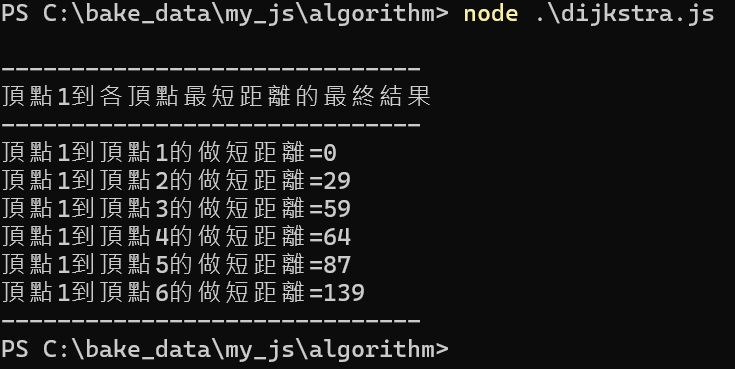
對於資訊安全而言,很難有一個十分嚴謹而明確的定義或標準。簡單來說,資訊安全(Information Security)的基本功能就是必須具備以下四種特性:
*秘密性(confidentiality):表示交易相關資料必須保密,當資料傳遞時,確保資料在網路上傳送不會遭截取、窺竊而洩漏資料內容,除了被授權的人,在網路上不怕被攔截或偷窺,而損害其秘密性。
*完整性(integrity):表示當資料送達時必須保證資料沒有被竄改的疑慮,訊息如遭竄改時,該筆訊息就會無效,例如由甲端傳至乙端的資料有沒有被竄改,乙端在收訊時,立刻知道資料是否完整無誤。
*認證性(authentication):表示當傳送方送出資料時,就必須能確認傳送者的身分是否為冒名,例如傳送方無法冒名傳送資料,持卡人、商家、發卡行、收單行和支付閘道,都必須申請數位憑證進行身分識別。
*不可否認性(non-repudiation):表示保證使用者無法否認他所完成過之資料傳送行為的一種機制,必須不易被複製及修改,就是指無法否認其傳送或接受訊息行為,例如收到金錢不能推說沒收到;同樣前用掉不能推收遺失,不能否認其未使用過。
11-1 輕鬆學會資料加密
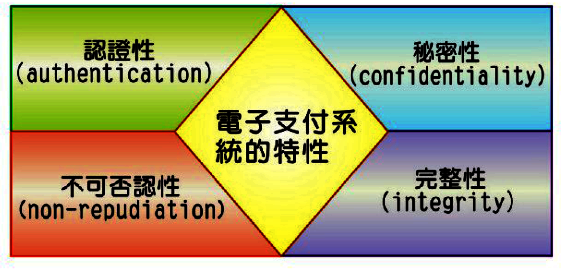
將資料轉換成不具任何意義的代碼,而這個處理過程就是(加密Encrypt)。資料再加密前稱為(明文 Plain text),經過加密後則稱為(密文 Cipher text)。
經過加密的資料在送抵目的端後,必須經過(解密 Decrypt)程序,才能將資料還原成原來的內容,而這個加/解密的機制則稱為(金鑰Key)。至於資料加密及解密的流程如下所示:
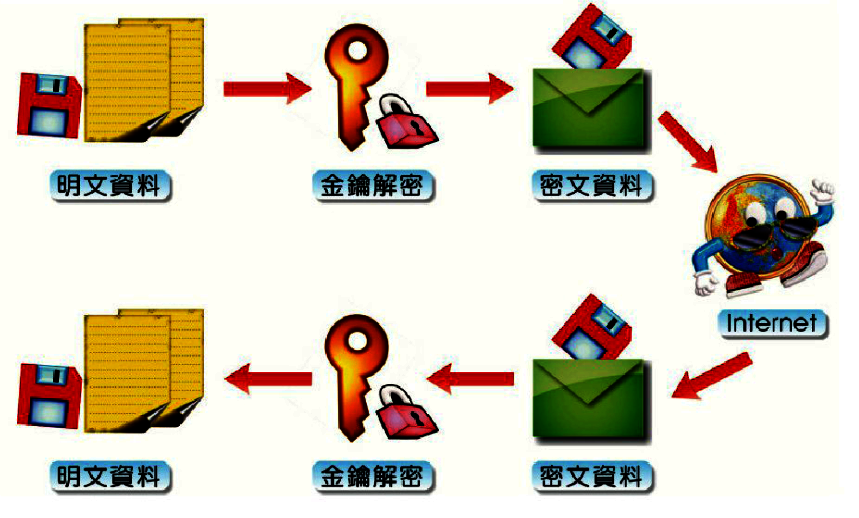
11-1-1 對稱鍵值加密系統
對稱鍵值機加密系統(Symmetrical key Encryption)又稱為單一鍵值加密系統(Single key Encryption)或秘密金鑰系統(Secret Key)。這種加密系統的運作方式,是由資料傳送者利用祕密金鑰(Secret Key)將文件加密,使文件成為一堆的亂碼後,再加以傳送。而接受者收到這個經過加密的密文後,再使用相同的祕密金鑰,將文件還原成原來的模樣。因為如果者B用這一組密碼解開文件,那麼就能確定這份文件是由使用者A加密後傳送過去,如下圖所示:
這種加密系統的運作方式較為單純,因此不論在加密及解密上的處理速度都相當快速。常見的對稱鍵值加密系統演算法有DES(Data Encryption Standard,資料加密標準)、Triple DES、IDEA(Internation Data Encryption Algorithm,國際資料加密演算法)等。
11-1-2非對稱鍵值加密系統與RSA演算法
(非對稱性加密系統)是目前較為普遍,也是金融界應用上最安全的加密系統,或稱為(雙鍵加密系統 Double key Encryption),這種加密系統主要的運作方式,是以兩把不同的金鑰(key)來對文件進行加/解密。例如使用者A要傳送一份新的文件給文件使用者B,使用者A會利用使用者B的公開金鑰來加密,並將祕文傳送給使用者B。當使用者收到密文後,再利用自己的私密金鑰解密。如下圖所示:
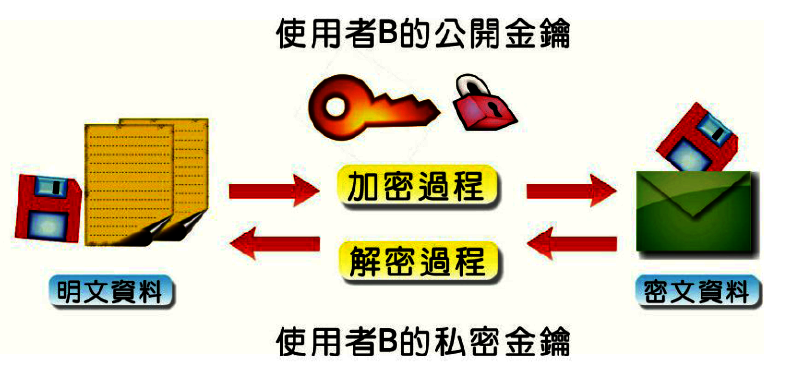
例如RSA(Rivest-Shamir-Adleman)是加密演算法中是一種非對稱加密演算法,在RSA演算法之前,加密方法幾乎都是對稱型的,非對稱是因為它利用兩個不同的鑰匙,一把叫公開金鑰,另外一把較私密金鑰。1977年由Ron Rivest、Adi Shamir 和 Leonard Adleman 一起提出的,RSA就是由三人姓氏開頭字母所組成。
11-2 一學就懂得雜湊演算法
雜湊法是利用雜湊函數來計算一個鍵值所對應的位址,進而建立雜湊表格,且依賴雜湊函數來搜尋找到個鍵值存放在表格中的位址,搜尋速度與資料多少無關,在沒有碰撞和溢位下,一次讀取即可,更包括保密性高,因為不事先知道雜湊函數就無法搜尋的優點。
選擇雜湊函數時,要特別注意不宜過於複雜,設計原則上至少必須符合計算速度快與碰撞頻率盡量小兩項特點。常見的雜湊法有除法、中間平方法、摺疊法及數位分析法。
11-2-1 除法
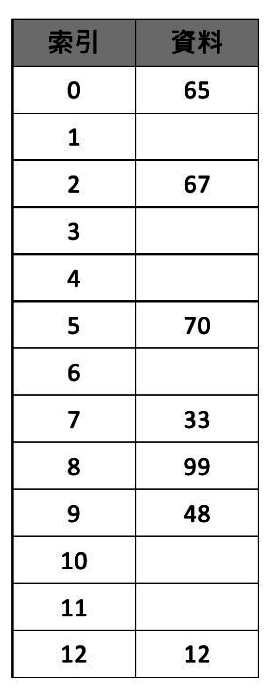
最簡單的雜湊法是將資料除以某一個常數後,取餘數來當索引。例如在一個有13個位置的陣列中,只使用到7個位址,值分別是12,65,70,99,33,67,48。那我們就可以把陣列內的值除以13,並以其餘數來當索引,我們可以用下例式子來表示:
h(key)=key mod B
在這個例子中,我們所使用的B=13。一般而言,會建議各位在選擇B時,B最好是質數。而上例所建立出來的雜奏表如所示:
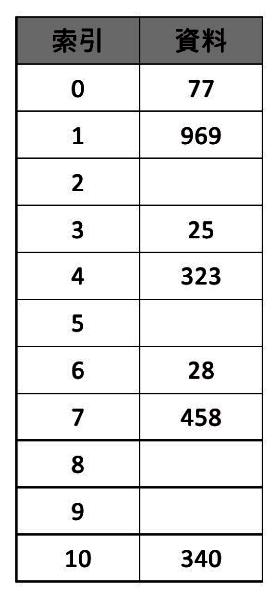
以下我們將用除法作為雜湊函數,將下列數字儲存在11空間:323,458,340,28,969,77,請問其雜湊表外觀為何?
令雜湊函數為h(key)=key mod B,其中B=11為一質數,這個函數的計算結果介於0-10之間(包括0及10二數),則h(323)=4、h(458)=7、h(25)=3、h(340)=10、h(28)=6、h(969)=1、h(77)=0。
11-2-2 中間平方法
中間平方法和除法相當類似,它是把資料乘以自己,之後再取中間的某段數字做索引。在下例中我們用中間平方法,並將它放在100個位址空間,其操作步驟如下:
1. 將12,65,70,99,33,67,51平方後如下:
144,4225,4900,9801,1089,4489,2601
2.我們取百位數及十位數作為鍵值,分別為:
14,22,90,80,08,48,60
上述這7個數字的數列就是對應原先12,65,70,99,33,67,51等7個數字存放在100個位址空間的索引鍵值,即
f(14)=12
f(22)=65
f(90)=70
f(80)=99
f(08)=33
f(48)=67
f(60)=51